

Di balik kecanggihan model pemrosesan bahasa modern, seperti klasifikasi sentimen otomatis dan deteksi ujaran kebencian, terdapat satu komponen utama: BERTForSequenceClassification. Model ini menjadi andalan dalam banyak proyek Natural Language Processing (NLP) karena mampu memahami konteks kalimat secara menyeluruh, bahkan dalam bahasa-bahasa yang kompleks seperti Bahasa Indonesia.
“Kalau GPT jago bicara, maka BERT jago memahami. Untuk klasifikasi teks, BERT menangkap makna kalimat secara bidirectional—membaca dari kiri dan kanan sekaligus,” jelas Galih Setiawan Nurohim, M.Kom, dosen Sistem Informasi Universitas Bina Sarana Informatika Kampus Solo.
Namun, apa yang sebenarnya terjadi di balik model ini? Galih menjelaskan bahwa memahami alur logika model sering kali lebih membantu dibanding langsung menyelami kode Python.
Bagan Kerja BERTForSequenceClassification
Alih-alih menghadapi tumpukan kode program, Galih menyarankan pendekatan visual untuk memahami alur kerja BERTForSequenceClassification. Berikut bagan ringkasnya:
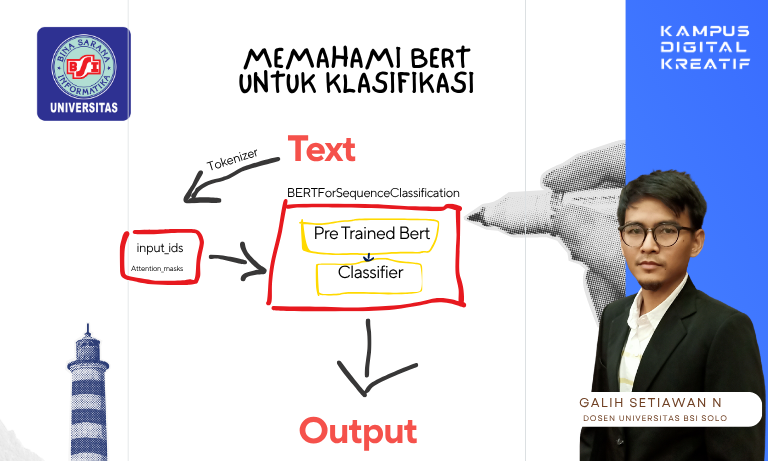
Langkah Demi Langkah: Menyusuri Jalur Inferensi BERT
- Input Teks
Proses dimulai dari kalimat biasa, seperti “Layanan rumah sakit ini sangat baik.”. - Tokenizer
Kalimat dipecah menjadi potongan-potongan kata yang sesuai dengan kosakata BERT, lalu diubah menjadi input_ids dan attention_mask. - BERT Encoder
Seluruh rangkaian token diproses oleh encoder BERT. Di sinilah konteks antar kata dianalisis dengan cara bidirectional (dua arah). - [CLS] Token
BERT menambahkan token khusus [CLS] di awal. Vektor hasil dari token ini menjadi representasi keseluruhan kalimat. - Linear Layer
Vektor [CLS] kemudian masuk ke lapisan linear (fully connected), yang bertugas memetakan informasi tadi ke jumlah kelas (misal: positif, negatif, netral). - Prediksi Kelas
Output akhirnya berupa probabilitas antar kelas yang bisa langsung dikonversi menjadi label (seperti dalam klasifikasi sentimen, berita, atau emosi).
Simpel, Tapi powerful
“Meski hanya terdiri dari beberapa blok, BERTForSequenceClassification menang karena kekuatan representasi kontekstualnya. Kita hanya perlu satu token [CLS] untuk memahami seluruh kalimat,” kata Galih.
Model ini telah digunakan dalam berbagai tugas NLP berbahasa Indonesia, termasuk klasifikasi emosi komentar media sosial, analisis opini publik, hingga sistem moderasi otomatis di forum daring.
Mengapa Ini Penting?
Memahami arsitektur seperti BERTForSequenceClassification secara visual membantu menghindari jebakan teknis berlebih. Tanpa memahami dasar ini, penerapan model di industri akan lebih banyak mengandalkan copy-paste daripada benar-benar dimengerti dan dioptimalkan.
Menurut Galih, pendekatan berbasis pemahaman diagram dan logika alur sangat penting untuk mempercepat transfer pengetahuan ke mahasiswa dan tim engineering.
Visualisasi semacam ini adalah jembatan dari teori ke praktik. Ketika memahami tiap bagian alur mulai dari tokenizer hingga prediksi maka model sebesar apapun bisa didekati dengan tenang. Dan dari situlah lahir model-model NLP canggih berbasis BERT yang kini digunakan di banyak aplikasi industri, pemerintahan, hingga pendidikan.



